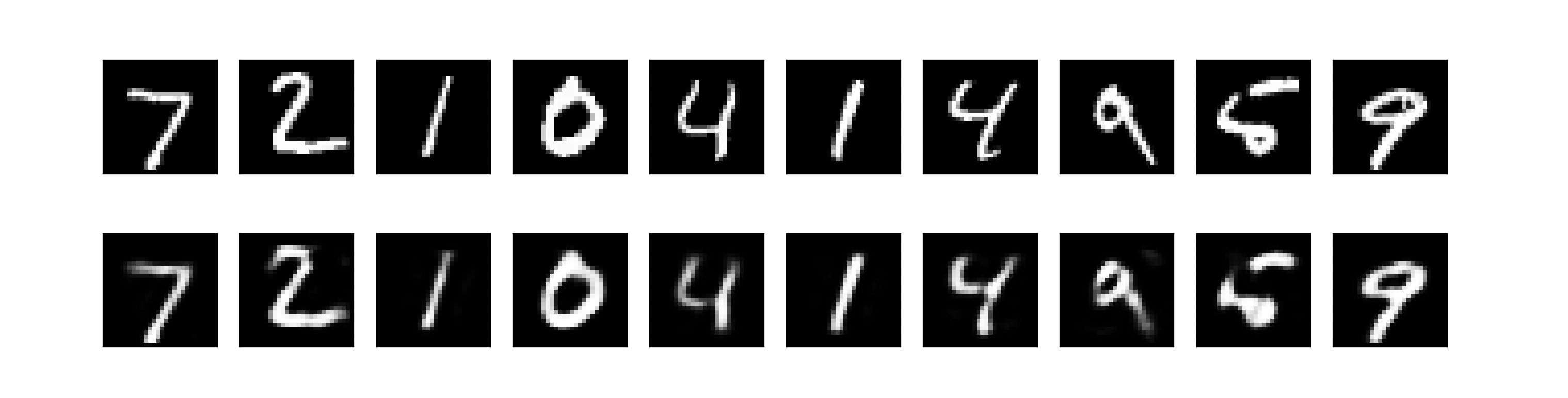案例介绍
在这个案例中,我们将使用自编码器(Autoencoder)来构建一个图像降噪的模型。我们将使用MNIST手写数字数据集作为我们的训练数据,并通过自编码器恢复图像中的噪声。
算法原理
自编码器是一种无监督学习算法,它通过训练数据来学习输入数据的低维表示。自编码器由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入数据映射到一个低维空间中,而解码器则将低维表示映射回原始输入空间。在训练过程中,自编码器目标是最小化输入与重构输出之间的重构误差,以便学习到数据的压缩表示。
自编码器的目标函数如下所示:
$$L(x, \hat{x}) = \|x – \hat{x}\|^2$$
其中,$x$是输入数据,$\hat{x}$是重构输出,$\|\|$表示欧几里得距离。
数据集
我们将使用MNIST数据集,它包含了大小为28×28的手写数字图像,以及对应的标签。
计算步骤
- 导入必要的库和模块
- 准备训练数据
- 构建自编码器模型
- 编译模型
- 训练模型
- 验证模型
- 对图像进行降噪
Python代码示例
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
# 准备训练数据
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 784))
x_test = np.reshape(x_test, (len(x_test), 784))
# 构建自编码器模型
input_shape = (784,)
encoding_dim = 32
input_img = Input(shape=input_shape)
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
# 编译模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 训练模型
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# 验证模型
decoded_imgs = autoencoder.predict(x_test)
# 对图像进行降噪
import matplotlib.pyplot as plt
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# 显示原图像
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示重构图像
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()代码细节解释
首先,我们导入需要的库和模块。然后,通过mnist.load_data()函数加载MNIST数据集,并进行预处理,将像素值归一化为0到1的范围,并将图像从28×28的二维数组转换为784维的一维数组。
接下来,我们定义了自编码器的模型结构。在这个例子中,我们使用单一的编码层和单一的解码层。编码层维度为32,解码层维度为784。模型的输入是784维的向量,输出也是784维的向量。
然后,我们编译了模型,使用Adam优化器和二进制交叉熵损失函数。
接下来,我们使用训练数据训练模型。我们将训练集作为输入和标签,并进行50个epoch的训练。训练期间的batch大小为256。
训练完成后,我们使用测试集验证模型。我们使用训练好的自编码器对测试集中的图像进行重构,并存储在decoded_imgs变量中。
最后,我们展示了部分原始图像和对应的重构图像。我们使用Matplotlib库绘制图像,并将原图像和重构图像放在一行中进行对比展示。