哈喽,我是cos大壮!
今天给大家分享的是关于 XGBoost的内容~
果然共性的问题,大家接收频率较高,这几天有同学反馈 之前分享的几篇文章,大家都或多或少遇到,而且特别有用。
今天把XGBoost方面6方面问题进行了汇总,有问题大家可以私信~
- 数据准备问题
- 参数调优问题
- 防止过拟合和欠拟合问题
- 特征工程问题
- 理解模型输出问题
- 调参策略问题
咱们答读者问,这个是第 8 期:突破最强算法 – XGBoost!!
好了,继续大标题分类以及具体的Question,废话不多说,咱们一起来看看~
再有问题,随时私信哈!不限XGBoost!
数据准备问题
读者问:壮哥好!这几天在处理数据时候,数据中有一些非数值型的特征,应该怎么处理才能在XGBoost中使用呢?这方面有什么技巧吗?有空的时候可以帮我看看
大壮答:你好,一般情况下,在XGBoost中处理非数值型特征通常需要进行特征工程的处理,因为XGBoost是一种基于树模型的算法,只能处理数值型的特征。
这里总结了一些常见的技巧,你可以先看看:
1. 标签编码
将非数值型特征映射为整数。对于每个类别,分配一个唯一的整数值。这可以通过scikit-learn的LabelEncoder来实现。
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
data['categorical_feature'] = label_encoder.fit_transform(data['categorical_feature'])2. 独热编码
将非数值型特征转换为二进制形式,以表示每个类别是否存在。这可以通过pandas的get_dummies函数来实现。
data = pd.get_dummies(data, columns=['categorical_feature'])3. 目标编码
使用目标变量的统计信息(例如均值)代替类别标签。这有助于保留类别之间的关系,并且对于高基数分类特别有用。
target_mean = data.groupby('categorical_feature')['target'].mean()
data['categorical_feature_encoded'] = data['categorical_feature'].map(target_mean)4. 频率编码
使用每个类别的出现频率来替代类别标签。这也有助于保留类别之间的相对关系。
freq_encoding = data['categorical_feature'].value_counts(normalize=True)
data['categorical_feature_encoded'] = data['categorical_feature'].map(freq_encoding)5. Embedding编码
对于高基数的非数值型特征,可以使用嵌入(Embedding)层来学习表示。这在神经网络中较为常见,可以通过PyTorch实现。
import torch
import torch.nn as nn
class EmbeddingNet(nn.Module):
def __init__(self, num_embeddings, embedding_dim):
super(EmbeddingNet, self).__init__()
self.embedding = nn.Embedding(num_embeddings, embedding_dim)
def forward(self, x):
return self.embedding(x)
# 使用例子
embedding_model = EmbeddingNet(num_embeddings=len(data['categorical_feature'].unique()), embedding_dim=10)
embedded_data = torch.tensor(data['categorical_feature'].values, dtype=torch.long)
result = embedding_model(embedded_data)6. 自定义变换
根据业务逻辑,可以使用其他自定义的方法来将非数值型特征转换为数值型特征。
在实际应用中,可以根据数据的性质和问题的要求选择合适的方法。同时,建议使用交叉验证等技术来评估不同的编码方式对模型性能的影响。
再具体的实践中,尤其是在使用XGBoost等模型时,需要根据具体问题和数据集的特点进行权衡和选择。
再有问题可以私信~
参数调优问题
读者问:想问下,一般情况下,子样本比例和列采样比例是什么,我应该怎样调整这些参数呢?
大壮答:你好,在XGBoost中,子样本比例和列采样比例是两个重要的超参数,分别用于控制每棵树的训练数据和特征的采样比例。
这两个参数的调整可以对模型的性能产生显著影响。
1. 子样本比例(subsample):
- 定义: 表示每棵树的训练样本的比例。取值范围在0到1之间。
- 作用: 控制每棵树对训练数据的采样比例,可以防止过拟合。
- 调整方法: 如果模型过拟合,可以减小该值;如果模型欠拟合,可以适度增加。
params = {
'subsample': 0.8 # 例如,设置子样本比例为0.8
}2. 列采样比例(colsample_bytree):
- 定义: 表示每棵树的特征采样比例。取值范围在0到1之间。
- 作用: 控制每棵树对特征的采样比例,可以增加模型的多样性。
- 调整方法: 如果特征维度较高,可以适度减小该值;如果模型对特征过拟合,可以增大该值。
params = {
'colsample_bytree': 0.9 # 例如,设置列采样比例为0.9
}3. 其他相关参数:
- XGBoost还有其他与采样相关的参数,例如
colsample_bylevel(每层的列采样比例)和colsample_bynode(每个节点的列采样比例)。这些参数可以根据实际情况进行调整。
params = {
'colsample_bylevel': 0.8, # 例如,设置每层的列采样比例为0.8
'colsample_bynode': 0.7 # 例如,设置每个节点的列采样比例为0.7
}4. 调参流程:
- 通过交叉验证等方式,尝试不同的子样本比例和列采样比例的组合。
- 可以使用Grid Search或Random Search等调参方法,寻找最优的超参数组合。
5. 一个完整示例:
- 以下是一个简单的XGBoost模型训练和调参的示例代码:
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 加载数据集
data = load_boston()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# 定义参数
params = {
'objective': 'reg:squarederror',
'subsample': 0.8,
'colsample_bytree': 0.9,
'max_depth': 3,
'learning_rate': 0.1,
'n_estimators': 100
}
# 创建模型
model = xgb.XGBRegressor(**params)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
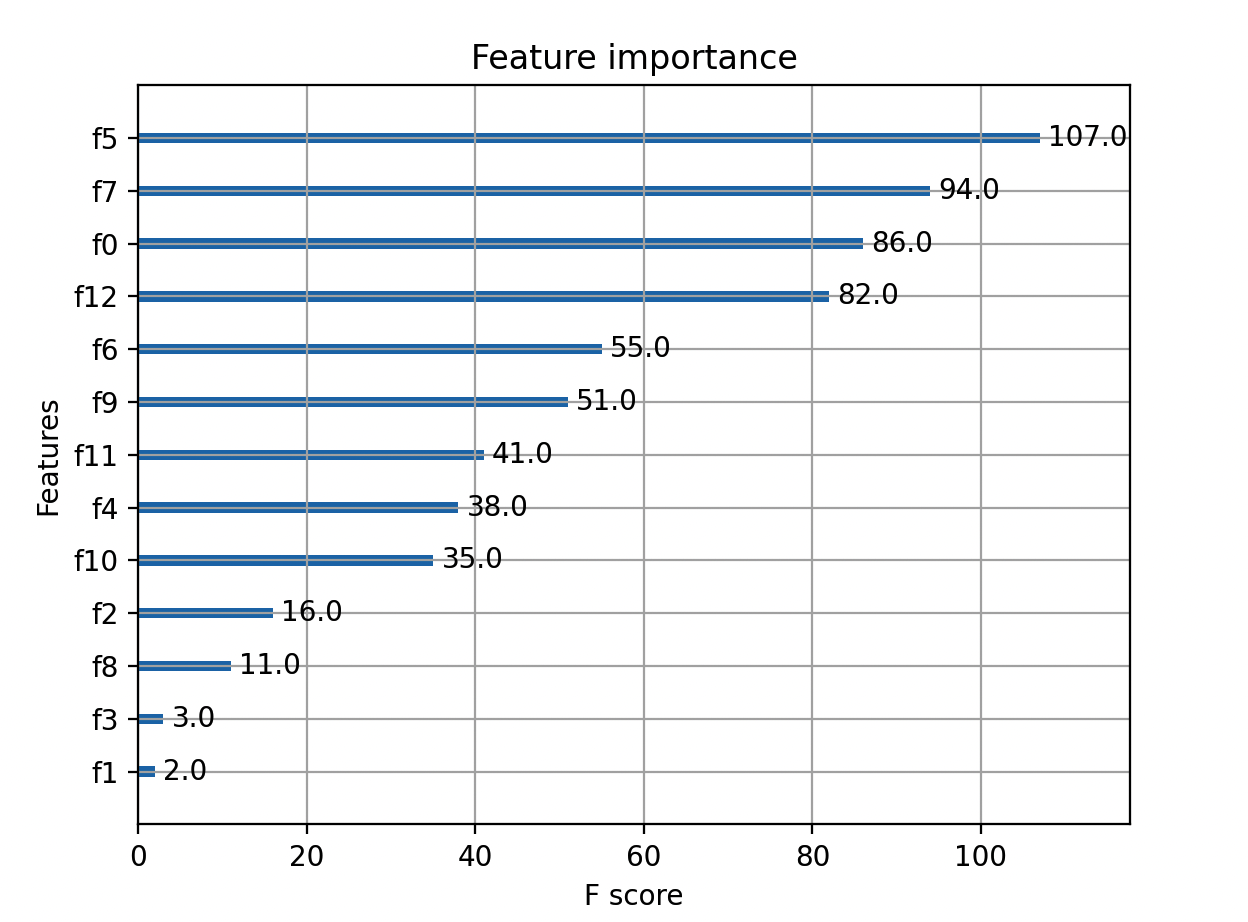
# 画出特征重要性图
xgb.plot_importance(model)
plt.show()上述代码中,subsample和colsample_bytree分别设置了子样本比例和列采样比例,其他参数可以根据具体情况调整。特征重要性图可用于进一步分析模型的表现。

防止过拟合和欠拟合问题
读者问:我看了Early Stopping的内容,还是不太通透,是用来防止过拟合的吗?它怎么在XGBoost中使用?
大壮答:哈喽,是防止过拟合的。Early Stopping 是用来防止过拟合的一种技术,它在训练模型过程中监控模型的性能指标,并在模型性能停止提升时提前停止训练,从而防止模型在训练集上过度拟合,提高模型的泛化能力。
在 XGBoost 中,Early Stopping 的主要目标是监控验证集(validation set)的性能,并在性能不再提升时停止训练。
下面总结是在 XGBoost 中如何使用 Early Stopping 的一般步骤:
- 准备数据集: 将数据集划分为训练集和验证集,通常采用交叉验证的方式。
- 定义模型: 使用 XGBoost 的 Python 接口(xgboost 包)定义一个基本的模型,设置好基本参数,如 learning rate、max depth 等。
- 配置 Early Stopping 参数: 设置 Early Stopping 相关的参数,主要包括
early_stopping_rounds和eval_metric。early_stopping_rounds表示在验证集上连续多少轮(boosting rounds)性能没有提升时停止训练。eval_metric是用来评估模型性能的指标,例如,可以选择使用 ‘logloss’ 作为评估指标。 - 训练模型: 使用训练数据集拟合模型,同时传入验证数据集,以便监控模型在验证集上的性能。
- 应用 Early Stopping: 在训练过程中,当连续指定的轮数上验证集上的性能没有提升时,训练将提前停止。这是通过设置
early_stopping_rounds参数实现的。
最后,我这里写了一个代码示例:
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 加载示例数据集
boston = load_boston()
X, y = boston.data, boston.target
# 划分训练集和验证集
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
# 转换数据为 DMatrix 格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dvalid = xgb.DMatrix(X_valid, label=y_valid)
# 定义模型参数
params = {
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'eta': 0.1,
'max_depth': 5,
'subsample': 0.8,
'colsample_bytree': 0.8
}
# 定义 Early Stopping 参数
early_stopping_rounds = 10
# 训练模型并应用 Early Stopping
evals_result = {} # 用于存储评估指标的历史记录
model = xgb.train(params, dtrain, num_boost_round=1000, evals=[(dtrain, 'train'), (dvalid, 'valid')],
evals_result=evals_result, early_stopping_rounds=early_stopping_rounds, verbose_eval=True)
# 评估模型在测试集上的性能
y_pred = model.predict(dvalid, ntree_limit=model.best_ntree_limit)
mse = mean_squared_error(y_valid, y_pred)
print(f"Mean Squared Error on Validation Set: {mse}")
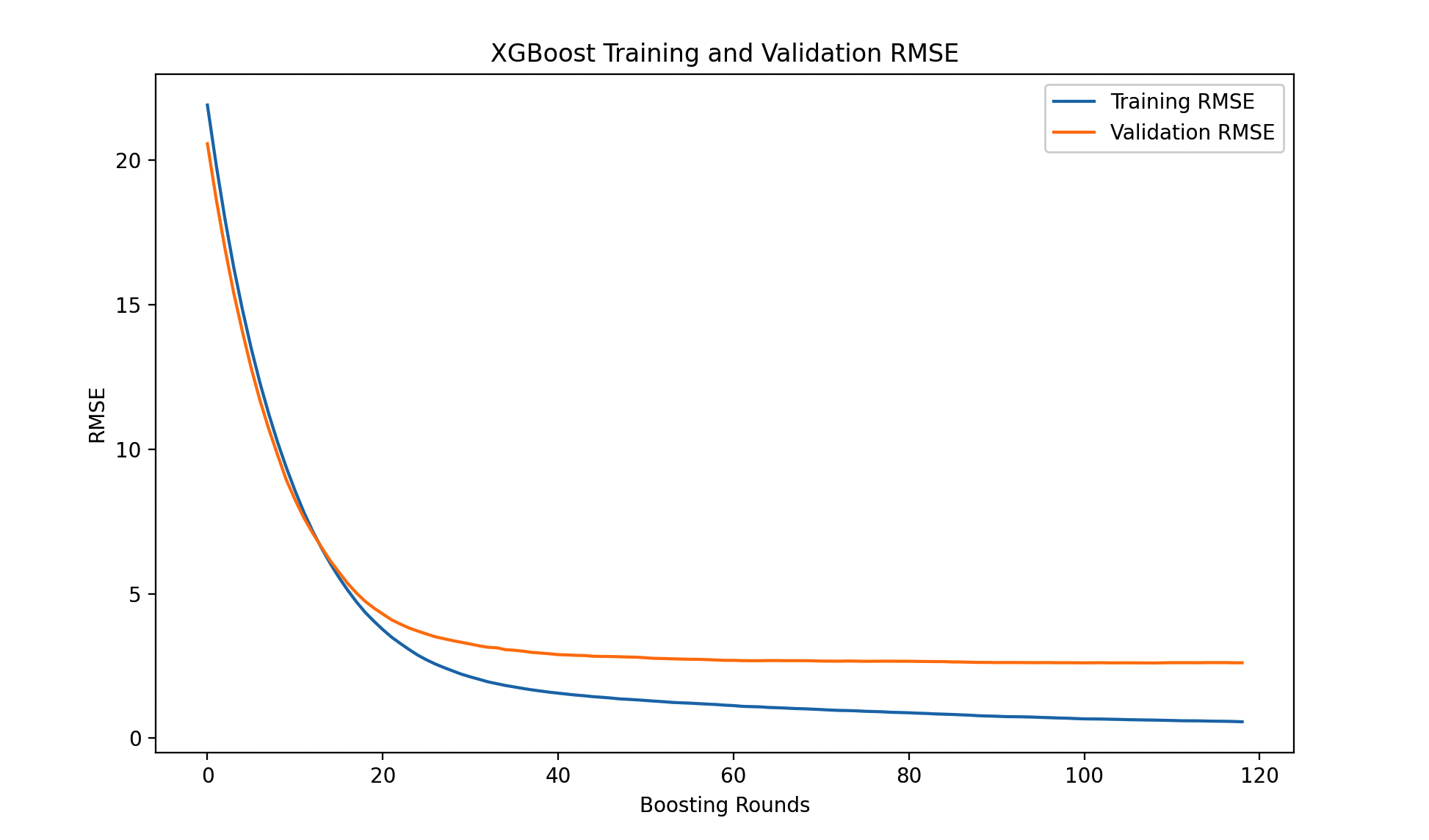
# 可视化模型在训练过程中的性能指标变化
train_metric = evals_result['train']['rmse']
valid_metric = evals_result['valid']['rmse']
plt.figure(figsize=(10, 6))
plt.plot(train_metric, label='Training RMSE')
plt.plot(valid_metric, label='Validation RMSE')
plt.xlabel('Boosting Rounds')
plt.ylabel('RMSE')
plt.title('XGBoost Training and Validation RMSE')
plt.legend()
plt.show()
上面的例子中,模型将在验证集上进行性能监控,如果连续 10 轮(可根据实际情况调整)上性能没有提升,训练将停止。最后,代码通过绘制性能随训练轮次的变化图展示了模型的训练过程。

特征工程问题
读者问:大壮哥,我刚刚开始学习想问一个问题,交叉特征是啥?创建新特征有助于提高模型性能吗?
大壮答:你好,在你的实验中,交叉特征通常是指通过将不同特征的组合作为新特征引入模型,以捕捉特征之间的相互作用关系。这样的特征工程手段有助于提高模型性能,因为它们能够更好地捕捉数据中的非线性关系和交互效应。通过引入交叉特征,模型能够更好地适应数据的复杂性,从而提高对目标的预测能力。
这就是交叉特征的提供的能力。所以是非常重要的,重要性我这边总结了几点:
- 捕捉非线性关系: 通过引入交叉特征,模型能够更好地捕捉不同特征之间的非线性关系,从而提高模型的表达能力。
- 增加信息量: 交叉特征能够引入新的信息,帮助模型更好地理解数据中隐藏的模式和规律。
- 处理特征之间的交互效应: 数据中的特征通常不是孤立存在的,它们之间存在着复杂的交互效应。通过引入交叉特征,模型能够更好地捕捉这些交互效应,提高模型的泛化能力。
- 增加模型复杂度: 交叉特征的引入增加了模型的复杂度,使其更能够适应复杂的数据结构,提高了对未见数据的预测能力。
下面我写了一个例子,假设我们有两个特征 x1 和 x2,通过引入交叉特征 x1 * x2,可以捕捉到 x1 和 x2 之间的乘法关系。通过这个例子,你可以先看看~
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import xgboost as xgb
from sklearn.metrics import accuracy_score
# 创建示例数据
np.random.seed(42)
X = pd.DataFrame({'x1': np.random.rand(100), 'x2': np.random.rand(100)})
y = (3*X['x1'] + 2*X['x2'] + 0.5*X['x1']*X['x2'] + 0.1*np.random.randn(100) > 0).astype(int)
# 使用LabelEncoder将y转换为从0开始的整数标签
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42, stratify=y_encoded)
# 建立XGBoost模型
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")我们在这个例子中,通过引入交叉特征 x1 * x2,我们增加了模型对数据的拟合能力,提高了分类的准确率。实际中,交叉特征的选择和创建需要根据具体问题和数据的特点来进行,可以使用领域知识或特征重要性等方法来指导特征工程的过程。
有问题可以继续私信哈~
理解模型输出问题
读者问:模型中每棵树的结构和决策路径是什么,该怎么理解呢?
大壮答:是这样。每棵树的结构和决策路径是由多个决策节点和叶子节点组成的。XGBoost采用了梯度提升算法,通过迭代地训练一系列的决策树,并将它们组合起来形成一个强大的集成模型。
1. 决策节点(Split Node):在每棵树的节点上,都存在一个决策条件,该条件基于输入特征的某个阈值。决策节点将数据集划分成两个子集,按照特征值是否满足该条件进行划分。
$$
\text{{split condition: }} f_i < \text{{threshold}}
$$
其中,$f_i$ 是选择的特征,$text{{threshold}}$ 是该特征的阈值。
2. 叶子节点(Leaf Node):在树的末端,叶子节点包含一个预测值。当输入样本通过树的决策路径达到某个叶子节点时,该叶子节点的预测值将被用于最终的模型预测。
3. 树的结构:XGBoost中的每棵树都是深度有限的,通过限制树的深度可以有效防止过拟合。树的结构是由决策节点和叶子节点的层次组成,形成了一个二叉树结构。树的深度通常由超参数来控制。
4. 决策路径:每个样本在树上通过一条决策路径,从根节点开始,根据每个节点上的决策条件逐步向下移动,直到达到叶子节点。决策路径就是样本在树上经过的一系列决策节点,这些节点的决策条件构成了样本的决策过程。
5. 理解决策路径:通过分析每棵树的结构和决策路径,我们可以了解模型是如何对输入特征进行组合和加权的。重要的特征将在树的上层节点上出现,而不太重要的特征可能在树的深层节点上出现。决策路径也反映了模型是如何对不同特征进行组合以做出最终预测的。
最后,咱们使用PyTorch实现的XGBoost可以通过xgboost库来完成。为了理解每棵树的结构和决策路径,可以使用plot_tree函数来可视化单棵树。
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
# 创建一个虚构数据集
np.random.seed(42)
X_train = np.random.rand(100, 5) # 假设有100个样本,每个样本有5个特征
y_train = np.random.rand(100) # 对应的目标变量
# 创建 XGBoost 模型
model = xgb.XGBRegressor()
# 训练模型
model.fit(X_train, y_train)
# 可视化第一棵树
plt.figure(figsize=(20, 10))
xgb.plot_tree(model, num_trees=0, rankdir='LR')
plt.show()
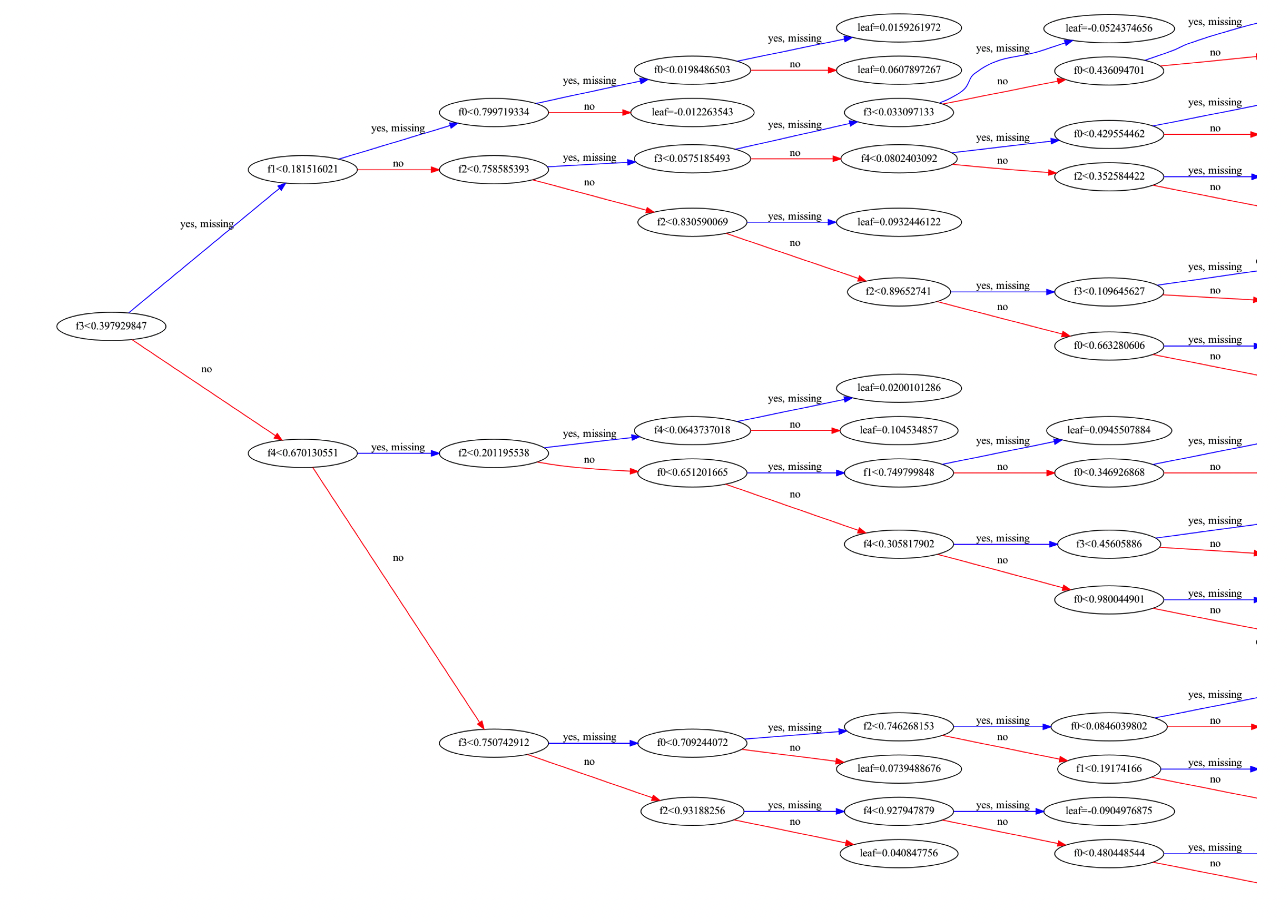
通过这个可视化,你可以看到树的结构、每个节点上的特征和阈值,以及叶子节点上的输出值,这样可以更好地理解模型的决策路径。
总的来说吧,理解XGBoost模型中每棵树的结构和决策路径有助于我们深入了解模型是如何进行预测的,从而更好地进行模型解释和调优。
调参策略问题
读者问:网格搜索和随机搜索有什么不同呢?在调参时,我应该选择哪一种方法?
大壮答:ok,先要知道的是,网格搜索(Grid Search)和随机搜索(Random Search)都是常用的调参方法,它们的主要区别在于搜索参数空间的方式。
下面详细阐述这两种方法的不同之处,以及在调参时选择哪种方法的考虑因素。
1. 网格搜索
- 原理: 网格搜索是一种穷举搜索的方法,它在预定义的参数空间内,通过在每个参数的所有可能组合上进行搜索。通过指定不同的参数组合,网格搜索遍历所有可能的组合,以找到最优的参数。
- 优点: 简单直观,能够穷尽搜索空间,找到全局最优解的可能性较高。
- 缺点: 计算开销较大,尤其是当参数空间较大时,需要花费大量的时间和计算资源。
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {
'learning_rate': [0.1, 0.01, 0.001],
'max_depth': [3, 5, 7],
'n_estimators': [50, 100, 200]
}
# 创建GridSearchCV对象
grid_search = GridSearchCV(estimator=xgboost_model, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)2. 随机搜索
- 原理: 随机搜索通过在参数空间内随机采样一组参数,然后评估模型性能。这个过程重复多次,直到达到指定的搜索次数或时间。相比于网格搜索,随机搜索更注重随机性,通过随机采样更广泛地探索参数空间。
- 优点: 计算开销相对较小,能够在较短时间内找到较好的参数组合。
- 缺点: 不一定能找到全局最优解,但可以在较短时间内找到一个较好的局部最优解。
from sklearn.model_selection import RandomizedSearchCV
# 定义参数分布
param_dist = {
'learning_rate': [0.1, 0.01, 0.001],
'max_depth': [3, 5, 7],
'n_estimators': [50, 100, 200]
}
# 创建RandomizedSearchCV对象
random_search = RandomizedSearchCV(estimator=xgboost_model, param_distributions=param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)3. 选择方法的考虑因素
- 计算资源: 如果计算资源充足,可以考虑使用网格搜索,以确保穷尽搜索空间。如果计算资源有限,可以选择随机搜索。
- 参数空间: 如果参数空间较小,网格搜索可能是一个不错的选择。如果参数空间较大,随机搜索更具优势。
- 时间效率: 如果时间有限,随机搜索可能更适合,因为它在相对短的时间内能够找到较好的参数组合。
总体而言,网格搜索和随机搜索都是有效的调参方法,选择取决于实际情况。在实践中,你也可以结合使用这两种方法,先使用随机搜索缩小搜索空间,然后在缩小后的空间中使用网格搜索进行更精细的调参。