案例介绍
在这个案例中,我们将使用决策树回归来预测波士顿地区的房屋价格。通过给定一些特征变量(如平均房间数、犯罪率等),我们的目标是预测对应房屋的房价。
算法原理
决策树回归是一种基于树结构的回归模型,它通过将特征空间划分为不同的区域,每个区域内具有相同的目标变量值,并通过构建决策树来实现预测。
决策树回归的关键思想是根据特征的取值进行划分,选择最优的划分特征和划分点,使得划分后的子集内目标变量的方差最小化。具体的算法原理如下:
- 计算当前节点的目标变量的方差,即平方误差和;
- 对每个特征的每个可能取值进行划分,计算划分后的子集的平方误差和;
- 选择划分特征和划分点,使得划分后的平方误差和最小;
- 递归地继续划分子集,直到满足停止条件,例如达到最大深度、节点包含的样本数小于某个阈值等。
公式推导
假设我们有一个数据集$D$,其中包含$n$个样本,每个样本包括$d$个特征变量和一个目标变量。我们的目标是通过构建决策树来建立回归模型。
对于回归问题,我们的目标是最小化平方误差和:
$$\text{MSE} = \frac{1}{n}\sum_{i=1}^{n}(y_i – \hat{y_i})^2$$
其中,$y_i$是样本$i$的真实目标变量值,$\hat{y_i}$是决策树预测的目标变量值。
决策树回归的算法过程可以通过递归地构建二叉树来实现,其中每个节点代表一个特征变量,每个叶节点代表一个预测值。
为了找到最佳划分特征和划分点,我们可以使用贪婪算法,依次评估每个特征的每个划分点,并选择最小的平方误差和。
数据集
我们使用sklearn库中的波士顿房屋价格数据集。这个数据集包含了506个样本,每个样本有13个特征变量和一个连续的目标变量(房屋价格中位数)。
计算步骤
- 加载数据集,并将其划分为训练集和测试集;
- 创建决策树回归模型,并设置相关参数;
- 使用训练集训练模型;
- 使用测试集评估模型性能,并计算预测结果的平均绝对误差和均方根误差;
- 可视化决策树模型。
Python代码示例
# 导入所需的库和模块
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.tree import export_graphviz
import pydot
# 加载波士顿房屋价格数据集
boston = load_boston()
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2, random_state=42)
# 创建决策树回归模型
regressor = DecisionTreeRegressor(max_depth=4)
# 训练模型
regressor.fit(X_train, y_train)
# 预测
y_pred = regressor.predict(X_test)
# 计算平均绝对误差和均方根误差
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
print("Mean Absolute Error:", mae)
print("Mean Squared Error:", mse)
# 可视化决策树模型
dot_data = export_graphviz(regressor, out_file=None, feature_names=boston.feature_names, filled=True)
graph = pydot.graph_from_dot_data(dot_data)[0]
graph.write_png('decision_tree.png')代码细节解释
- 从sklearn.datasets导入load_boston,用于加载波士顿房屋价格数据集。
- 从sklearn.model_selection导入train_test_split,用于划分数据集为训练集和测试集。
- 从sklearn.tree导入DecisionTreeRegressor,用于创建决策树回归模型。
- 从sklearn.metrics导入mean_absolute_error和mean_squared_error,用于计算模型性能指标。
- 从sklearn.tree导入export_graphviz,用于可视化决策树模型。
- 加载波士顿房屋价格数据集,并将数据集划分为训练集和测试集。
- 创建决策树回归模型,并设置相关参数,如最大深度。
- 使用训练集训练模型。
- 使用测试集进行预测。
- 计算预测结果的平均绝对误差和均方根误差。
- 可视化决策树模型,并保存为PNG格式的图片文件。

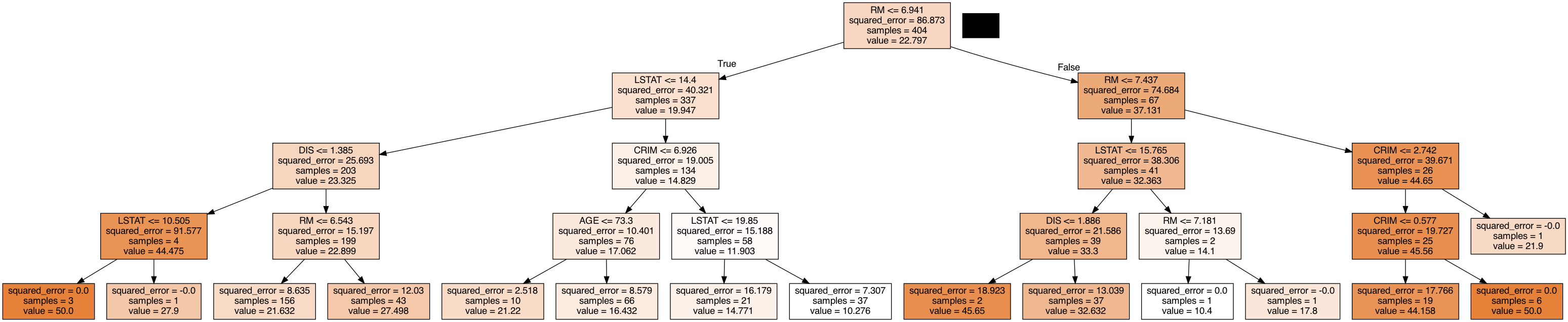
通过以上代码,我们可以训练一个决策树回归模型,并使用该模型预测波士顿房屋价格。最后,我们可视化生成的决策树模型,以便更好地理解模型的决策过程。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论(3)
绘制网络图时出现:“dot” not found in path,具体解决办法为:
1、下载绘图软件graphviz
https://gitlab.com/api/v4/projects/4207231/packages/generic/graphviz-releases/9.0.0/windows_10_cmake_Release_graphviz-install-9.0.0-win64.exe
2、双击安装,勾选加入环境变量。如果忘记勾选,后期手工加入,类似Java安装时需要将%JAVA_HOME%\bin加入Path变量中一样。
3、在python安装环境下找到pydot.py文件,若是虚拟环境或者Anaconda环境的话直接到相应的python目录中查找即可,打开此文件找到第1274行,将self.prog = ‘dot’修改为:
import platform
sys = platform.system()
if sys == “Windows”:
self.prog = ‘dot.exe’
elif sys == “Linux”:
self.prog = ‘dot’
(4)再次执行代码应该不再出现错误。
最后一句输出png,pycharm提示”Unresolved attribute reference ‘write_png’ for class ‘Dot’ ”
改正方法,将其改为graph.write(‘decision_tree.png’, format=’png’)
如果从本地采用如下方法加载数据集:
file_path = ‘../data/boston_housing.csv’
# 从CSV文件中读取数据
boston_df = pd.read_csv(file_path)
# 分离特征和目标变量
X = boston_df.drop(‘TARGET’, axis=1)
y = boston_df[‘TARGET’]
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
需要将可视化决策树模型一行feature_names=boston.feature_names改为feature_names=X.columns
dot_data = export_graphviz(regressor, out_file=None, feature_names=X.columns, filled=True)